MOOSE Stochastic Tools Module (STM)
July 2026
Introduction
The STM is an open-source MOOSE module available to all MOOSE-based applications.
Provide a MOOSE-like interface for performing stochastic analysis on MOOSE-based models.
Sample parameters, run applications, and gather data that is both efficient (memory and runtime) and scalable.

Perform UQ and sensitivity analysis with distributed data and leveraging advanced variance reduction methods.

Train meta-models to build fast-evaluating surrogates of the high-fidelity multiphysics model and provide a pluggable interface for these surrogates.
Harness machine learning capabilities through the C++ front end of PyTorch, i.e. LibTorch.
Use active learning models for building surrogates.
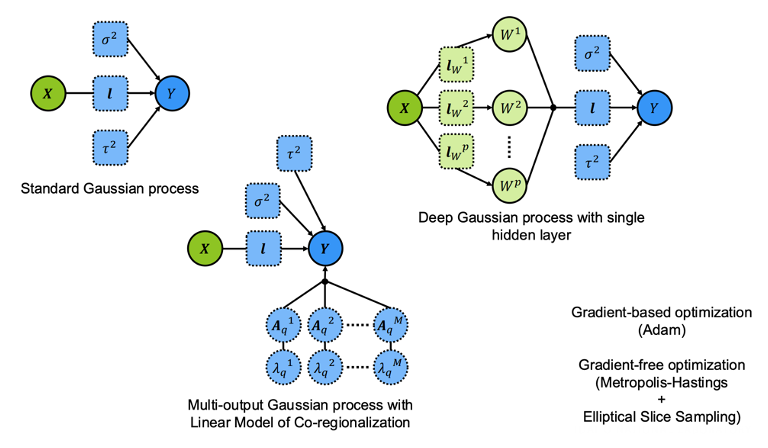
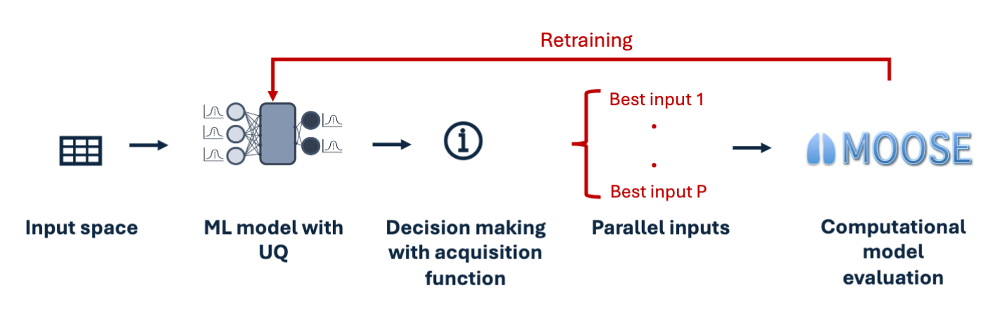
Focus of this Training
Part 1: Introduction to systems and basic parameter studies
Model execution via MultiApps
Parameter study statistics and sensitivity analysis
Introduction to surrogate system
Part 2*: Bayesian (inverse) uncertainty quantification
Model parameter uncertainties
Model parameter + noise uncertainties
Model parameter + noise + model inadequacy uncertainties
Part 3*: Active learning
Training a Gaussian process surrogate with Monte Carlo sampling
Use of an acquisition function
Solving optimization problems with Bayesian optimization
* Not included in these slides yet
Workflow
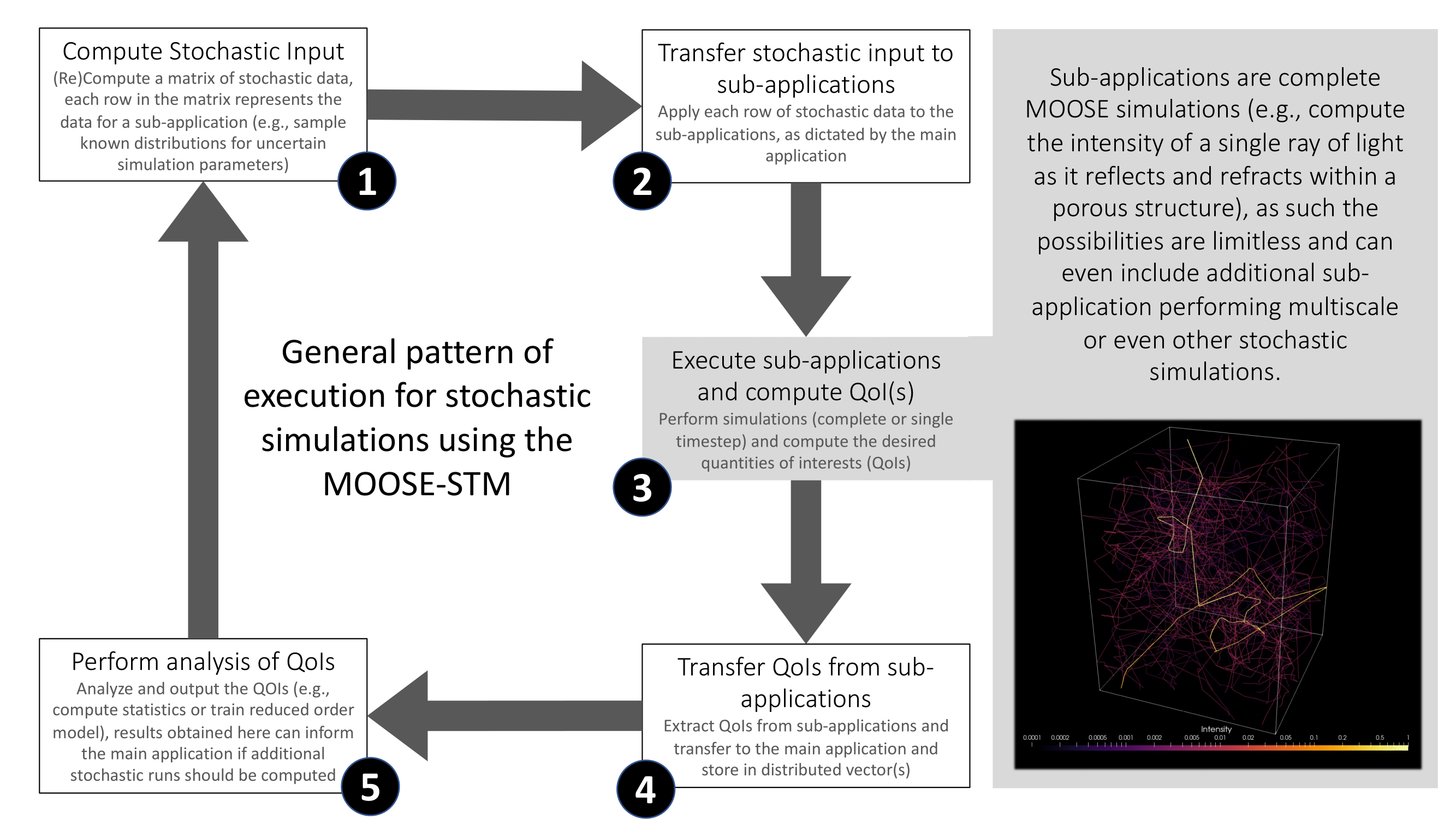
Stochastic Tools Syntax
Since STM runs as a wrapper, it does not have typical MOOSE physics objects
The use of this syntax produces a minimal FEM problem required by the MOOSE system
[StochasticTools]
[]
With this block, the following typical objects are no longer required:
Mesh
Variables
Kernels
Executioner
Example Problem Statement
Governing Equation
Physics Input
[Mesh<<<{"href": "../../../syntax/Mesh/index.html"}>>>]
type = GeneratedMesh
dim = 2
nx = 10
ny = 10
[]
[Variables<<<{"href": "../../../syntax/Variables/index.html"}>>>/T]
initial_condition<<<{"description": "Specifies a constant initial condition for this variable"}>>> = 300
[]
[Kernels<<<{"href": "../../../syntax/Kernels/index.html"}>>>]
[time]
type = ADTimeDerivative<<<{"description": "The time derivative operator with the weak form of $(\\psi_i, \\frac{\\partial u_h}{\\partial t})$.", "href": "../../../source/kernels/ADTimeDerivative.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
[]
[diff]
type = ADMatDiffusion<<<{"description": "Diffusion equation Kernel that takes an isotropic Diffusivity from a material property", "href": "../../../source/kernels/MatDiffusion.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
diffusivity<<<{"description": "The diffusivity value or material property"}>>> = diffusivity
[]
[source]
type = ADBodyForce<<<{"description": "Demonstrates the multiple ways that scalar values can be introduced into kernels, e.g. (controllable) constants, functions, and postprocessors. Implements the weak form $(\\psi_i, -f)$.", "href": "../../../source/kernels/BodyForce.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
value<<<{"description": "Coefficient to multiply by the body force term"}>>> = 100
[]
[]
[BCs<<<{"href": "../../../syntax/BCs/index.html"}>>>]
[left]
type = ADDirichletBC<<<{"description": "Imposes the essential boundary condition $u=g$, where $g$ is a constant, controllable value.", "href": "../../../source/bcs/ADDirichletBC.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = left
value<<<{"description": "Value of the BC"}>>> = 300
[]
[right]
type = ADNeumannBC<<<{"description": "Imposes the integrated boundary condition $\\frac{\\partial u}{\\partial n}=h$, where $h$ is a constant, controllable value.", "href": "../../../source/bcs/NeumannBC.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = right
value<<<{"description": "For a Laplacian problem, the value of the gradient dotted with the normals on the boundary."}>>> = -100
[]
[]
[Materials<<<{"href": "../../../syntax/Materials/index.html"}>>>/constant]
type = ADGenericConstantMaterial<<<{"description": "Declares material properties based on names and values prescribed by input parameters.", "href": "../../../source/materials/GenericConstantMaterial.html"}>>>
prop_names<<<{"description": "The names of the properties this material will have"}>>> = 'diffusivity'
prop_values<<<{"description": "The values associated with the named properties"}>>> = 1
[]
[Executioner<<<{"href": "../../../syntax/Executioner/index.html"}>>>]
type = Transient
num_steps = 4
dt = 0.25
[]
[Postprocessors<<<{"href": "../../../syntax/Postprocessors/index.html"}>>>]
[T_avg]
type = ElementAverageValue<<<{"description": "Computes the volumetric average of a variable", "href": "../../../source/postprocessors/ElementAverageValue.html"}>>>
variable<<<{"description": "The name of the variable that this object operates on"}>>> = T
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'initial timestep_end'
[]
[q_left]
type = ADSideDiffusiveFluxAverage<<<{"description": "Computes the average of the diffusive flux over the specified boundary", "href": "../../../source/postprocessors/SideDiffusiveFluxAverage.html"}>>>
variable<<<{"description": "The name of the variable which this postprocessor integrates"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = left
diffusivity<<<{"description": "The name of the diffusivity material property that will be used in the flux computation. This must be provided if the variable is of finite element type"}>>> = diffusivity
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'initial timestep_end'
[]
[]
[Controls<<<{"href": "../../../syntax/Controls/index.html"}>>>/stochastic]
type = SamplerReceiver<<<{"description": "Control for receiving data from a Sampler via SamplerParameterTransfer.", "href": "../../../source/controls/SamplerReceiver.html"}>>>
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
[]
moose-opt -i diffusion.i
# moose-opt can be any application executable
# that includes the Stochastic Tools Module.
Postprocessor Values:
+----------------+----------------+----------------+
| time | T_avg | q_left |
+----------------+----------------+----------------+
| 0.000000e+00 | 3.000000e+02 | 1.026734e-13 |
| 2.500000e-01 | 2.945503e+02 | 1.691165e+01 |
| 5.000000e-01 | 2.903864e+02 | 1.162035e+01 |
| 7.500000e-01 | 2.876841e+02 | 5.770252e+00 |
| 1.000000e+00 | 2.859939e+02 | 1.733798e+00 |
+----------------+----------------+----------------+
Parameters and Quantities of Interest (QoIs)
Four uncertain parameters:
| Parameter | Symbol | Syntax | Distribution |
|---|---|---|---|
| Diffusivity | Materials/constant/prop_values | Uniform(0.5, 2.5) | |
| Source | Kernel/source/function | Normal(100, 25) | |
| Temperature | BCs/left/value | Normal(300, 45) | |
| Flux | BCs/right/value | Weibull(1, 20, -110) |
Two quantities of interest:
| QoI | Symbol | Syntax |
|---|---|---|
| Average Temperature | Postprocessors/T_avg | |
| Left Heat Flux | Postprocessors/q_left |
Sampling Methods
Samplers
Samplers define a "sampling matrix" used for stochastic analysis
is the number of rows and is the number of columns
The number of rows is termed "number of samples"
The number of columns indicates the dimensionality of input space or "number of parameters"
A "sample" is a slice of the matrix at a given row, i.e.:
Where each entry is the value of a parameter at the given row
Random Sampling
Random sampling involves building a sampling matrix filled with pseudo-random numbers.
This random number is based on a probability "Distribution" defined for each column.
The process is to compute a pseudo-random number () and evaluate the quantile of the distribution.
[Samplers]
[mc]
type = MonteCarlo
distributions = 'uniform normal'
num_rows = 10
[]
[lhs]
type = LatinHypercube
distributions = 'uniform normal'
num_rows = 10
[]
[]
Distributions
Distribution objects are stand-alone classes that can be invoked by other objects as needed, very similar to the Functions system.
/**
* Compute the probability with given probability distribution function (PDF) at x
*/
virtual Real pdf(const Real & x) const = 0;
/**
* Compute the cumulative probability with given cumulative probability distribution (CDF) at x
*/
virtual Real cdf(const Real & x) const = 0;
/**
* Compute the inverse CDF (quantile function) value for given variable value y
*/
virtual Real quantile(const Real & y) const = 0;
[Distributions]
[uniform]
type = Uniform
lower_bound = 0
upper_bound = 20
[]
[normal]
type = Normal
mean = 1
standard_deviation = 0.1
[]
[]
Product Samplers
Cartesian product sampler takes the Kronecker of linearly spaced vectors.
Each vector is defined by three numbers: (1) start value, (2) step size, and (3) number of steps.
[Samplers]
[cartesian_product]
type = CartesianProduct
linear_space_items = '10 1.5 3
20 1 4
130 10 2'
[]
[]
Quadrature sampler creates an -dimensional quadrature based on PDF weigting functions.
Mainly meant to be used with PolynomialChaos.
Sparse quadrature options allow for efficient integration of monomial spaces.


[Samplers]
[quadrature]
type = Quadrature
distributions = 'uniform normal'
order = 4
sparse_grid = smolyak
[]
[]
Explicitly Defined Samplers
CSVSampler and InputMatrix samplers offer a way to explicitly define the sampling matrix.
Useful for using STM in a workflow where sampler values are generated externally.
[Samplers]
[csv]
type = CSVSampler
samples_file = 'samples.csv'
column_indices = '0 1 3'
[]
[matrix]
type = InputMatrix
matrix = '1 2 3 4 5 6;
10 20 30 40 50 60;
0.1 0.2 0.3 0.4 0.5 0.6;
2 4 6 8 10 12;
1 4 9 16 25 36'
[]
[]
Workshop Distributions and Sampler
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]
[Distributions<<<{"href": "../../../syntax/Distributions/index.html"}>>>]
[D]
type = Uniform<<<{"description": "Continuous uniform distribution.", "href": "../../../source/distributions/Uniform.html"}>>>
lower_bound<<<{"description": "Distribution lower bound"}>>> = 0.5
upper_bound<<<{"description": "Distribution upper bound"}>>> = 2.5
[]
[q]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 100
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 25
[]
[T_0]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 300
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 45
[]
[q_0]
type = Weibull<<<{"description": "Three-parameter Weibull distribution.", "href": "../../../source/distributions/Weibull.html"}>>>
location<<<{"description": "Location parameter (a or low)"}>>> = -110
scale<<<{"description": "Scale parameter (b or lambda)"}>>> = 20
shape<<<{"description": "Shape parameter (c or k)"}>>> = 1
[]
[]
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[hypercube]
type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 5000
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'D q T_0 q_0'
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sampling_matrix]
type = StochasticMatrix<<<{"description": "Tool for extracting Sampler object data and storing data from stochastic simulations.", "href": "../../../source/reporters/StochasticMatrix.html"}>>>
sampler<<<{"description": "The sample from which to extract distribution data."}>>> = hypercube
sampler_column_names<<<{"description": "Prescribed names of sampler columns, used to assign names of outputted vectors."}>>> = 'D q T_0 q_0'
parallel_type<<<{"description": "This parameter will determine how the stochastic data is gathered. It is common for outputting purposes that this parameter be set to ROOT, otherwise, many files will be produced showing the values on each processor. However, if there are lot of samples, gathering on root may be memory restrictive."}>>> = ROOT
[]
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
csv<<<{"description": "Output the scalar variable and postprocessors to a *.csv file using the default CSV output."}>>> = true
[]Execution Using MultiApps
Parallelism of Sampling Matrix
Every row of the sampling matrix is assigned one or more processors.
The processors(s) assigned to a row are responsible for evaluating that sample.
Here are some examples:
5 Rows and 3 Processors
5 Rows and 8 Processors
5 Rows and 8 Processors (ensuring every row has 2 processors)
Sampling Using MultiApps
Create/run sub-applications for each sampler row.
SamplerFullSolveMultiApp fully evaluates each row before transferring data.
The vast majority of applications will use SamplerFullSolveMultiApp
SamplerTransientMultiApp progresses each sample in time and transfers data at each step.
min_procs_per_app = <n>parameter ensures that at leastnprocessor are used for each sampleUse for large problems where memory is an issue and problem already scales well
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = mc
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'sub.i'
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-reset
[]
[][MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerTransientMultiApp<<<{"description": "Creates a sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerTransientMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = mc
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'sub.i'
[]
[]
[Executioner<<<{"href": "../../../syntax/Executioner/index.html"}>>>]
type = Transient
num_steps = 5
[]MultiApp Mode
normal: One sub-application is created for each row of data supplied by the Sampler object.
batch-reset: One sub-application is created for each processor, this sub-application is destroyed and re-created for each row of data supplied by the Sampler object.
batch-restore: One sub-application is created for each processor, this sub-application is backed up after initialization. Then for each row of data supplied by the Sampler object the sub-application is restored to the initial state prior to execution.
Normal Mode
Batch Mode
MultiApp Mode (cont.)
normal mode
Traditional method of running multiple sub-applications (
positions).Very memory intensive and not recommended for production use.
[MultiApps/runner]
type = SamplerFullSolveMultiApp
...
mode = normal
[]batch-reset mode
Recommended mode for general problems and non-intrusive.
Not memory intensive, but not the most efficient by run-time.
[MultiApps/runner]
...
mode = batch-reset
[]batch-restore mode
Works if parameters are controllable.
[MultiApps/runner]
...
mode = batch-restore
[]batch-restore mode with re-used solution
Works for steady-state and pseudo-transient problems.
Keeps solution for next sample (better initial guess)
[MultiApps/runner]
...
mode = batch-restore
keep_solution_during_restore = true
[]batch-restore mode with no restore
Most efficient method, but only works for steady-state problems.
Skips all restoring operations and just calls
solve()again.
[MultiApps/runner]
...
mode = batch-restore
no_backup_and_restore = true
[]MultiApp Mode (cont.)


Transferring Sampler Quantities
Using command-line syntax (normal and batch-reset modes)
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[sub]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = sample
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'sub.i'
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-reset
[]
[]
[Controls<<<{"href": "../../../syntax/Controls/index.html"}>>>]
[cmdline]
type = MultiAppSamplerControl<<<{"description": "Control for modifying the command line arguments of MultiApps.", "href": "../../../source/controls/MultiAppSamplerControl.html"}>>>
multi_app<<<{"description": "The name of the MultiApp to control."}>>> = sub
sampler<<<{"description": "The Sampler object to utilize for altering the command line options of the MultiApp."}>>> = sample
param_names<<<{"description": "The names of the command line parameters to set via the sampled data."}>>> = 'Mesh/xmax'
[]
[]
Using controllable parameters (batch-restore modes)
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[sub]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = sub.i
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = sample
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-restore
[]
[]
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[runner]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = sub
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = sample
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'BCs/left/value'
[]
[]In sub.i:
[Controls<<<{"href": "../../../syntax/Controls/index.html"}>>>]
[stm]
type = SamplerReceiver<<<{"description": "Control for receiving data from a Sampler via SamplerParameterTransfer.", "href": "../../../source/controls/SamplerReceiver.html"}>>>
[]
[]Transferring QoIs
SamplerReporterTransfer can gather all the different types of values into a single object
Postprocessors have the syntax
<pp_name>/valueVectorPostprocessors have the syntax
<vpp_name>/<vector_name>Reporters have the syntax
<reporter_name>/<value_name>
Unlike other transfers, the data does not need to be declared explicitly on the main application.
A StochasticReporter object just needs to exist.
The transfer will declare values programmatically into the
stochastic_reporterobject.
The resulting value will be a vector of with the length of the number of sampler rows
A vector of scalars for postprocessors
A vector of vectors for vector-postprocessors
parallel_type = ROOTgathers all the data accross processors so that there is a single file on output.
QoI Output
The resulting data will have the name
<stochastic_reporter_name>/<transfer_name>:<object_name>:<value_name>The
convergedvector tells you whether or not the sample's sub-application was able to solveVector QoIs are not able to be outputted to CSV
main_out.json:
"storage": {
"data:avg_u:value": [
290.0493845242595,
248.6050947481139,
...
],
"data:converged": [
true,
true,
...
]
"data:u_line:u": [
[
290.0493845242595,
283.2398742039828,
...
],
[
248.6050947481139,
245.2938472398621,
...
],
...
],
}
main_out_storage_0001.csv:
data:avg_u:value,data:converged
290.0493845242595,True
248.6050947481139,True
...
Dealing with Failed Solves
It may happen that the sub-application is not able to solve with a certain set of parameters.
Having
ignore_solve_not_converge = truewill ignore the error caused when a sample's sub-application fails to solve.Transient problems must also have
error_on_dtmin = falsein the sub-application executioner.Transfers will send whatever the last computed value of the QoI is.
[MultiApps]
[runner]
...
ignore_solve_not_converge = true
[]
[]
[Executioner]
type = Transient
...
error_on_dtmin = false
[]
Workshop MultiApps and Transfers
@@ -1,47 +1,76 @@
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]
[Distributions<<<{"href": "../../../syntax/Distributions/index.html"}>>>]
[D]
type = Uniform<<<{"description": "Continuous uniform distribution.", "href": "../../../source/distributions/Uniform.html"}>>>
lower_bound<<<{"description": "Distribution lower bound"}>>> = 0.5
upper_bound<<<{"description": "Distribution upper bound"}>>> = 2.5
[]
[q]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 100
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 25
[]
[T_0]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 300
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 45
[]
[q_0]
type = Weibull<<<{"description": "Three-parameter Weibull distribution.", "href": "../../../source/distributions/Weibull.html"}>>>
location<<<{"description": "Location parameter (a or low)"}>>> = -110
scale<<<{"description": "Scale parameter (b or lambda)"}>>> = 20
shape<<<{"description": "Shape parameter (c or k)"}>>> = 1
[]
[]
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[hypercube]
type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 5000
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'D q T_0 q_0'
[]
[]
+[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
+ [runner]
+ type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
+ sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = hypercube
+ input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'diffusion.i'
+ cli_args<<<{"description": "Additional command line arguments to pass to the sub apps. If one set is provided the arguments are applied to all, otherwise there must be a set for each sub app."}>>> = 'Outputs/console=false'
+ mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-restore
+ []
+[]
+
+[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
+ [parameters]
+ type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
+ to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
+ sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
+ parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values
+ Kernels/source/value
+ BCs/left/value
+ BCs/right/value'
+ []
+ [results]
+ type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
+ from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
+ sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
+ stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = sampling_matrix
+ from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'T_avg/value q_left/value'
+ []
+[]
+
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sampling_matrix]
type = StochasticMatrix<<<{"description": "Tool for extracting Sampler object data and storing data from stochastic simulations.", "href": "../../../source/reporters/StochasticMatrix.html"}>>>
sampler<<<{"description": "The sample from which to extract distribution data."}>>> = hypercube
sampler_column_names<<<{"description": "Prescribed names of sampler columns, used to assign names of outputted vectors."}>>> = 'D q T_0 q_0'
parallel_type<<<{"description": "This parameter will determine how the stochastic data is gathered. It is common for outputting purposes that this parameter be set to ROOT, otherwise, many files will be produced showing the values on each processor. However, if there are lot of samples, gathering on root may be memory restrictive."}>>> = ROOT
[]
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
csv<<<{"description": "Output the scalar variable and postprocessors to a *.csv file using the default CSV output."}>>> = true
[](+ modules/stochastic_tools/examples/workshop/step02.i)
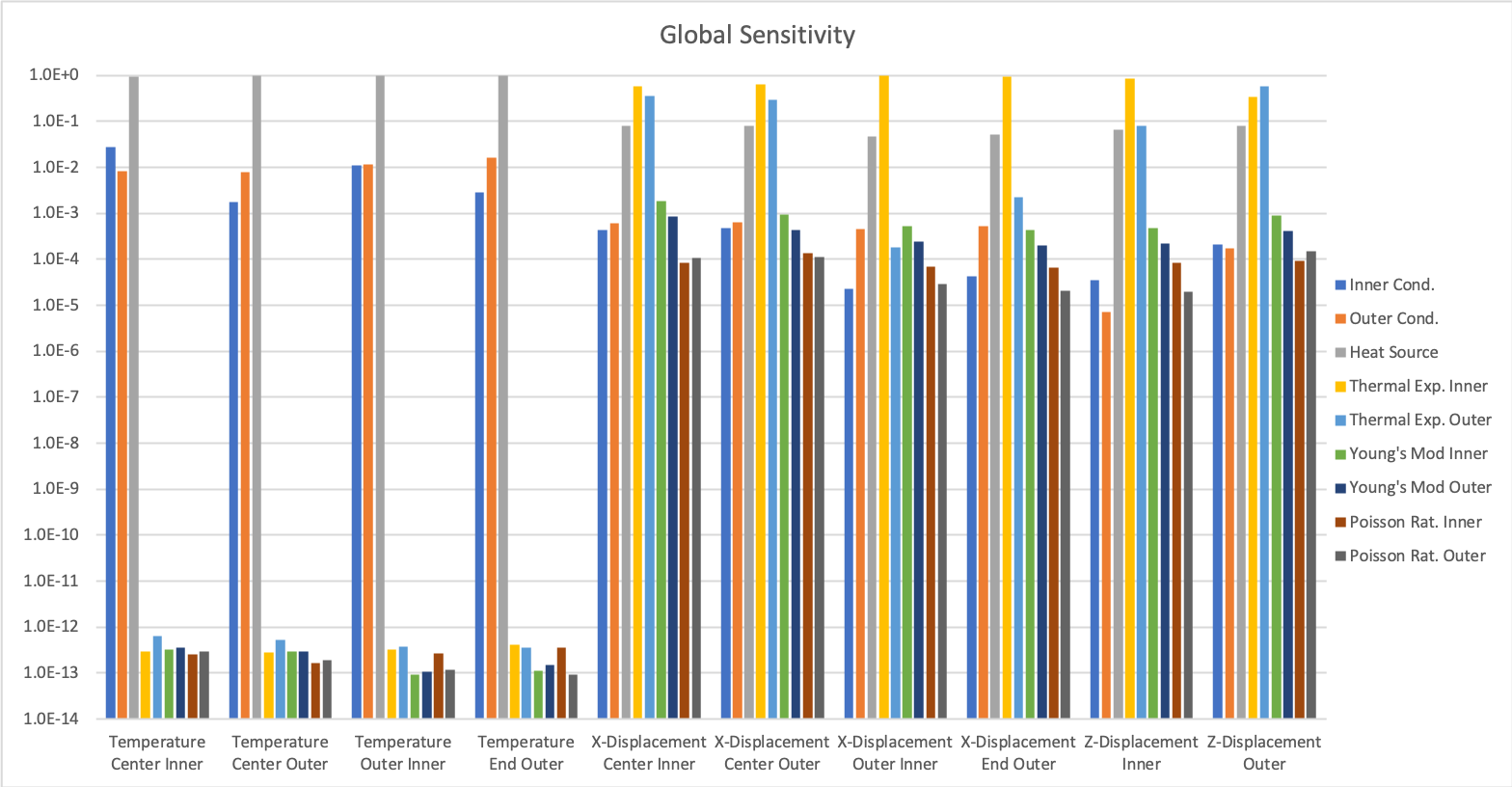
Sensitivity Analysis
Computing Statistical Moments
STM is able to compute statistics on the resulting distributed data.
Mean
Standard deviation
Median
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[stats]
type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'storage/data:const:num storage/data:const:int storage/data:const:vec'
compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'min max sum mean stddev norm2 ratio stderr median'
[]
[]Confidence Intervals
Confidence intervals are a way to determining how well the computed statistic is known.
The "ci_method"
= percentileoption (recommended) utilizes a bootstrap method:Shuffle the QoI vector a number of times to have that many new QoI vectors (shuffling causes repeated values).
Recompute the statistics on each QoI vector to produce a vector of statistics.
Sort the vector of statistics.
Select the value in the vector that is greater than the requested percent of values.
"ci_replicates" specifies the number of shuffles.
"ci_levels" specifies the percentile extracted (1%, 5%, 10%, 90%, 95%, and 99% are typical values).
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[stats]
type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = storage/data:const:num_vec
compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'mean stddev'
ci_method<<<{"description": "The method to use for computing confidence level intervals."}>>> = 'percentile'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.025 0.05 0.1 0.16 0.5 0.84 0.9 0.95 0.975'
ci_replicates<<<{"description": "The number of replicates to use when computing confidence level intervals."}>>> = 10000
ci_seed<<<{"description": "The random number generator seed used for creating replicates while computing confidence level intervals."}>>> = 1945
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = FINAL
[]
[]Sobol Sensitivities
Sobol indices are a global sensitivity analysis technique that can determine influence of parameter uncertainty on QoI uncertainty.
The SobolReporter object in conjunction with the Sobol sampler computes Sobol indices:
First-order and total indices indicate QoI sensitivity to a specific parameter
Second-order indices indicate non-linearities between two parameters
The Sobol sampler requires two other samplers.
Number of samples can be quite large with a large parameter space:
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[sample]
type = MonteCarlo<<<{"description": "Monte Carlo Sampler.", "href": "../../../source/samplers/MonteCarloSampler.html"}>>>
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'uniform uniform uniform uniform uniform uniform'
num_rows<<<{"description": "The number of rows per matrix to generate."}>>> = 10
seed<<<{"description": "Random number generator initial seed"}>>> = 0
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = PRE_MULTIAPP_SETUP
[]
[resample]
type = MonteCarlo<<<{"description": "Monte Carlo Sampler.", "href": "../../../source/samplers/MonteCarloSampler.html"}>>>
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'uniform uniform uniform uniform uniform uniform'
num_rows<<<{"description": "The number of rows per matrix to generate."}>>> = 10
seed<<<{"description": "Random number generator initial seed"}>>> = 1
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = PRE_MULTIAPP_SETUP
[]
[sobol]
type = Sobol<<<{"description": "Sobol variance-based sensitivity analysis Sampler.", "href": "../../../source/samplers/SobolSampler.html"}>>>
sampler_a<<<{"description": "The 'sample' matrix."}>>> = sample
sampler_b<<<{"description": "The 're-sample' matrix."}>>> = resample
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = PRE_MULTIAPP_SETUP
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sobol]
type = SobolReporter<<<{"description": "Compute SOBOL statistics values of a given VectorPostprocessor or Reporter objects and vectors.", "href": "../../../source/reporters/SobolReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'storage/data:const:gf storage/data:const:gfa storage/data:const:gf_vec'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.1 0.9'
ci_replicates<<<{"description": "The number of replicates to use when computing confidence level intervals."}>>> = 1000
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = FINAL
[]
[]Morris Filtering
Morris filtering is another global sensitivity technique.
Can require less computational effort than Sobol:
MorrisReportercomputes the and for each parameter:: no influential impact on the QoI.
: significant impact on the QoI.
: nonlinear or interactive effects.
: additive or linear
: negligible aggregate effect on the QoI while nonlinear perturbations (perturbing in more than one direction) can be significant.
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[morris]
type = MorrisSampler<<<{"description": "Morris variance-based sensitivity analysis Sampler.", "href": "../../../source/samplers/MorrisSampler.html"}>>>
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'uniform uniform uniform uniform uniform uniform'
trajectories<<<{"description": "Number of unique trajectories to perform. The higher number of these usually means a more accurate sensitivity evaluation, but it is proportional to the number of required model evaluations: 'trajectoris' x (number of 'distributions' + 1)."}>>> = 10
levels<<<{"description": "The number of levels in the sampling. This determines the discretization of the input space, more levels means finer discretization and more possible model perturbations."}>>> = 4
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = PRE_MULTIAPP_SETUP
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[morris]
type = MorrisReporter<<<{"description": "Compute global sensitivities using the Morris method.", "href": "../../../source/reporters/MorrisReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'storage/data:const:gf storage/data:const:gfa storage/data:const:gf_vec'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.1 0.9'
ci_replicates<<<{"description": "The number of replicates to use when computing confidence level intervals. This is basically the number of times the statistics are recomputed with a random selection of indices."}>>> = 1000
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = FINAL
[]
[]Workshop Statistics
@@ -1,76 +1,83 @@
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]
[Distributions<<<{"href": "../../../syntax/Distributions/index.html"}>>>]
[D]
type = Uniform<<<{"description": "Continuous uniform distribution.", "href": "../../../source/distributions/Uniform.html"}>>>
lower_bound<<<{"description": "Distribution lower bound"}>>> = 0.5
upper_bound<<<{"description": "Distribution upper bound"}>>> = 2.5
[]
[q]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 100
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 25
[]
[T_0]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 300
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 45
[]
[q_0]
type = Weibull<<<{"description": "Three-parameter Weibull distribution.", "href": "../../../source/distributions/Weibull.html"}>>>
location<<<{"description": "Location parameter (a or low)"}>>> = -110
scale<<<{"description": "Scale parameter (b or lambda)"}>>> = 20
shape<<<{"description": "Shape parameter (c or k)"}>>> = 1
[]
[]
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[hypercube]
type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 5000
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'D q T_0 q_0'
[]
[]
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = hypercube
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'diffusion.i'
cli_args<<<{"description": "Additional command line arguments to pass to the sub apps. If one set is provided the arguments are applied to all, otherwise there must be a set for each sub app."}>>> = 'Outputs/console=false'
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-restore
[]
[]
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[parameters]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values
Kernels/source/value
BCs/left/value
BCs/right/value'
[]
[results]
type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = sampling_matrix
from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'T_avg/value q_left/value'
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sampling_matrix]
type = StochasticMatrix<<<{"description": "Tool for extracting Sampler object data and storing data from stochastic simulations.", "href": "../../../source/reporters/StochasticMatrix.html"}>>>
sampler<<<{"description": "The sample from which to extract distribution data."}>>> = hypercube
sampler_column_names<<<{"description": "Prescribed names of sampler columns, used to assign names of outputted vectors."}>>> = 'D q T_0 q_0'
parallel_type<<<{"description": "This parameter will determine how the stochastic data is gathered. It is common for outputting purposes that this parameter be set to ROOT, otherwise, many files will be produced showing the values on each processor. However, if there are lot of samples, gathering on root may be memory restrictive."}>>> = ROOT
[]
+ [stats]
+ type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
+ reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'sampling_matrix/results:T_avg:value sampling_matrix/results:q_left:value'
+ compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'mean stddev'
+ ci_method<<<{"description": "The method to use for computing confidence level intervals."}>>> = 'percentile'
+ ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.05 0.95'
+ []
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
- csv<<<{"description": "Output the scalar variable and postprocessors to a *.csv file using the default CSV output."}>>> = true
+ json<<<{"description": "Output Reporter values to a *.json file using the default JSON output."}>>> = true
[](+ modules/stochastic_tools/examples/workshop/step03.i)
"stats": {
"sampling_matrix_results:T_avg:value_MEAN": [
292.04525124073933,
[
291.05955750899653,
293.03675897580734
]
],
"sampling_matrix_results:T_avg:value_STDDEV": [
42.48125197567408,
[
41.772628701872996,
43.178807046612356
]
],
"sampling_matrix_results:q_left:value_MEAN": [
7.717565253594722,
[
7.105391070784749,
8.33016456253632
]
],
"sampling_matrix_results:q_left:value_STDDEV": [
26.25982391894163,
[
25.552483239209632,
26.9620435963083
]
]
},
| QoI | Mean | Standard Deviation |
|---|---|---|
| 292 | 42.48 | |
| (5.0%, 95.0%) CI | (291.1, 293) | (41.77, 43.18) |
| 7.718 | 26.26 | |
| (5.0%, 95.0%) CI | (7.105, 8.33) | (25.55, 26.96) |
Workshop Sobol Statistics
@@ -1,76 +1,94 @@
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]
[Distributions<<<{"href": "../../../syntax/Distributions/index.html"}>>>]
[D]
type = Uniform<<<{"description": "Continuous uniform distribution.", "href": "../../../source/distributions/Uniform.html"}>>>
lower_bound<<<{"description": "Distribution lower bound"}>>> = 0.5
upper_bound<<<{"description": "Distribution upper bound"}>>> = 2.5
[]
[q]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 100
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 25
[]
[T_0]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 300
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 45
[]
[q_0]
type = Weibull<<<{"description": "Three-parameter Weibull distribution.", "href": "../../../source/distributions/Weibull.html"}>>>
location<<<{"description": "Location parameter (a or low)"}>>> = -110
scale<<<{"description": "Scale parameter (b or lambda)"}>>> = 20
shape<<<{"description": "Shape parameter (c or k)"}>>> = 1
[]
[]
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[hypercube]
type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
- num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 5000
+ num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 1000
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'D q T_0 q_0'
+ []
+ [resample]
+ type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
+ num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 1000
+ seed<<<{"description": "Random number generator initial seed"}>>> = 2025
+ distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'D q T_0 q_0'
+ []
+ [sobol]
+ type = Sobol<<<{"description": "Sobol variance-based sensitivity analysis Sampler.", "href": "../../../source/samplers/SobolSampler.html"}>>>
+ sampler_a<<<{"description": "The 'sample' matrix."}>>> = hypercube
+ sampler_b<<<{"description": "The 're-sample' matrix."}>>> = resample
+ resample<<<{"description": "Create the re-sample matrix for second-order indices."}>>> = false
[]
[]
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
- sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = hypercube
+ sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = sobol
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'diffusion.i'
cli_args<<<{"description": "Additional command line arguments to pass to the sub apps. If one set is provided the arguments are applied to all, otherwise there must be a set for each sub app."}>>> = 'Outputs/console=false'
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-restore
[]
[]
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[parameters]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
- sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
+ sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = sobol
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values
Kernels/source/value
BCs/left/value
BCs/right/value'
[]
[results]
type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
- sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
+ sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = sobol
stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = sampling_matrix
from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'T_avg/value q_left/value'
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sampling_matrix]
type = StochasticMatrix<<<{"description": "Tool for extracting Sampler object data and storing data from stochastic simulations.", "href": "../../../source/reporters/StochasticMatrix.html"}>>>
- sampler<<<{"description": "The sample from which to extract distribution data."}>>> = hypercube
+ sampler<<<{"description": "The sample from which to extract distribution data."}>>> = sobol
sampler_column_names<<<{"description": "Prescribed names of sampler columns, used to assign names of outputted vectors."}>>> = 'D q T_0 q_0'
parallel_type<<<{"description": "This parameter will determine how the stochastic data is gathered. It is common for outputting purposes that this parameter be set to ROOT, otherwise, many files will be produced showing the values on each processor. However, if there are lot of samples, gathering on root may be memory restrictive."}>>> = ROOT
+ []
+ [sobol]
+ type = SobolReporter<<<{"description": "Compute SOBOL statistics values of a given VectorPostprocessor or Reporter objects and vectors.", "href": "../../../source/reporters/SobolReporter.html"}>>>
+ sampler<<<{"description": "SobolSampler object."}>>> = sobol
+ reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'sampling_matrix/results:T_avg:value sampling_matrix/results:q_left:value'
+ ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.05 0.95'
[]
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
- csv<<<{"description": "Output the scalar variable and postprocessors to a *.csv file using the default CSV output."}>>> = true
+ json<<<{"description": "Output Reporter values to a *.json file using the default JSON output."}>>> = true
[](+ modules/stochastic_tools/examples/workshop/step04.i)
"sobol": {
"sampling_matrix_results:T_avg:value": {
"FIRST_ORDER": [
[
0.012886805005992073,
-0.005371699727822437,
0.94356770546739,
0.03229000337826293
],
[
[
-0.05868786206191532,
-0.09728839898174543,
0.7882128660752169,
-0.06928830708176942
],
[
0.08757250800355308,
0.07145037427674986,
1.0923493235473365,
0.14496698804687763
]
]
],
| (5.0%, 95.0%) CI | ||||
|---|---|---|---|---|
| 0.01289 | -0.005372 | 0.9436 | 0.03229 | |
| (-0.05869, 0.08757) | (-0.09729, 0.07145) | (0.7882, 1.092) | (-0.06929, 0.145) | |
| 0.07813 | 0.3364 | 0.1573 | 0.2562 | |
| (0.02931, 0.1329) | (0.2908, 0.3849) | (0.1229, 0.195) | (0.2183, 0.2961) |
Parameter Study Syntax
ParameterStudy
Action that simplifies syntax for simple parameter studies
No need to identify value names or run into common, annoying input errors.
Programmatic creation of
Samplers,Distributions,Controls,Transfers,Reporters, andOutputsobjects.Automatic multiapp mode detection
Workshop ParameterStudy
[ParameterStudy<<<{"href": "../../../syntax/ParameterStudy/index.html"}>>>]
input<<<{"description": "The input file containing the physics for the parameter study."}>>> = diffusion.i
parameters<<<{"description": "List of parameters being perturbed for the study."}>>> = 'Materials/constant/prop_values
Kernels/source/value
BCs/left/value
BCs/right/value'
quantities_of_interest<<<{"description": "List of the reporter names (object_name/value_name) that represent the quantities of interest for the study."}>>> = 'T_avg/value q_left/value'
sampling_type<<<{"description": "The type of sampling to use for the parameter study."}>>> = lhs
num_samples<<<{"description": "The number of samples to generate for 'monte-carlo' and 'lhs' sampling."}>>> = 5000
distributions<<<{"description": "The types of distribution to use for 'monte-carlo' and 'lhs' sampling. The number of entries defines the number of columns in the matrix."}>>> = 'uniform normal normal weibull'
uniform_lower_bound<<<{"description": "Lower bounds for 'uniform' distributions."}>>> = 0.5
uniform_upper_bound<<<{"description": "Upper bounds 'uniform' distributions."}>>> = 2.5
weibull_location<<<{"description": "Location parameter (a or low) for 'weibull' distributions."}>>> = -110
weibull_scale<<<{"description": "Scale parameter (b or lambda) for 'weibull' distributions."}>>> = 20
weibull_shape<<<{"description": "Shape parameter (c or k) for 'weibull' distributions."}>>> = 1
normal_mean<<<{"description": "Means (or expectations) of the 'normal' distributions."}>>> = '100 300'
normal_standard_deviation<<<{"description": "Standard deviations of the 'normal' distributions."}>>> = '25 45'
statistics<<<{"description": "The statistic(s) to compute for the study."}>>> = 'mean stddev'
ci_levels<<<{"description": "A vector of confidence levels to consider for statistics confidence intervals, values must be in (0, 1)."}>>> = '0.05 0.95'
[]Surrogate System
Introduction
STM Trainers/Surrogates provide a way of building reduced-order models that emulate high-fidelity multiphysics models.
These surrogates are meant to be much faster to evaluate than the high-fidelity model.
Usages for these surrogates:
Uncertainty quantification
Sensitivity analysis
Parameter optimization
Multi-scale modeling
Controller design
Digital twins
Process:
Produce response data using sampling/multiapp strategy.
Use Trainer object to compute meta data from predictor and response data.
Load trainer data to create Surrogate object.
Pick up Surrogate object to evaluate at inputted predictor values.
Trainers
Trainer objects take in predictor and response data.
Trainers need sampler to understand how data was parallelized.
Predictor data usually comes from sampler values, but can be from other data.
Most trainer objects have cross-validation capabilities to predict model performance.
Trainer data can be stored in a binary output to be loaded later.
[Trainers]
[linear_regression]
type = PolynomialRegressionTrainer
sampler = sample_train
response = 'storage/data:avg_u:value'
max_degree = 1
regression_type = ols
# Other options
# predictors = ''
# predictor_cols = ''
# response_type = real/vector_real
[]
[]
[Outputs]
[lm]
type = SurrogateTrainerOutput
trainers = linear_regression
[]
[]
Surrogates
Trainer data is loaded in a Surrogate object
Surrogate objects can be picked up by other objects and evaluated:
const SurrogateModel & model = getSurrogateModel("lm"); std::vector<Real> x = {1, 2}; Real y = model.evaluate(x);
[Surrogates]
[lm]
type = PolynomialRegressionSurrogate
trainer = linear_regression
# filename = 'lm_linear_regression.rd'
[]
[]
[Reporters]
[lm_evaluate]
type = EvaluateSurrogate
model = lm
sampler = sample_test
[]
[]
Cross Validation
Cross validation is a method to determine the quality of the surrogate.
The method involves splitting the predictor/response data into train and test parts.
Randomly select a portion of the data to train with.
Test the model with rest of the predictor data and compute error with the response data
Repeat with "folds" of randomly selected train-test parts.
The error is an indication of how the resulting model (trained with the full data set) fits the data
Large cross-validation scores indicates under-fitting.
Large variation in cross-validation scores indicates over-fitting.
[Trainers]
[trainer]
...
cv_type = k_fold
cv_splits = 5
cv_n_trials = 100
cv_surrogate = surrogate
[]
[]
[Surrogates]
[surrogate]
...
trainer = trainer
[]
[]
[Reporters]
[cv_scores]
type = CrossValidationScores
models = surrogate
[]
[]
Workshop Surrogate Input
Instead of running the physics application, we load a previous CSV file with the necessary data.
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[csv]
type = CSVSampler<<<{"description": "Sampler that reads samples from CSV file.", "href": "../../../source/samplers/CSVSampler.html"}>>>
samples_file<<<{"description": "Name of the CSV file that contains the samples matrix."}>>> = 'step02_out_sampling_matrix_0001.csv'
column_names<<<{"description": "Column names in the CSV file to be sampled from. Number of columns names here will be the same as the number of columns per matrix."}>>> = 'D q T_0 q_0 results:T_avg:value results:q_left:value'
[]
[resample]
type = Cartesian1D<<<{"description": "Provides complete Cartesian product for the supplied variables.", "href": "../../../source/samplers/Cartesian1DSampler.html"}>>>
linear_space_items<<<{"description": "A list of triplets, each item should include the min, step size, and number of steps."}>>> = '0.5 0.1 21
50 5 21
200 10 21
-100 2 26'
nominal_values<<<{"description": "Nominal values for each column."}>>> = '1 100 300 -100'
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[sampling_matrix]
type = StochasticMatrix<<<{"description": "Tool for extracting Sampler object data and storing data from stochastic simulations.", "href": "../../../source/reporters/StochasticMatrix.html"}>>>
sampler<<<{"description": "The sample from which to extract distribution data."}>>> = csv
sampler_column_names<<<{"description": "Prescribed names of sampler columns, used to assign names of outputted vectors."}>>> = 'D q T_0 q_0 T_avg q_left'
outputs<<<{"description": "Vector of output names where you would like to restrict the output of variables(s) associated with this object"}>>> = none
[]
[pr_T_avg_cv]
type = CrossValidationScores<<<{"description": "Tool for extracting cross-validation scores and storing them in a reporter for output.", "href": "../../../source/reporters/CrossValidationScores.html"}>>>
models<<<{"description": "Names of surrogate models."}>>> = pr_T_avg
[]
[evaluate]
type = EvaluateSurrogate<<<{"description": "Tool for sampling surrogate models.", "href": "../../../source/reporters/EvaluateSurrogate.html"}>>>
model<<<{"description": "Name of surrogate models."}>>> = pr_T_avg
sampler<<<{"description": "Sampler to use for evaluating surrogate models."}>>> = resample
parallel_type<<<{"description": "This parameter will determine how the stochastic data is gathered. It is common for outputting purposes that this parameter be set to ROOT, otherwise, many files will be produced showing the values on each processor. However, if there are lot of samples, gathering on root may be memory restrictive."}>>> = ROOT
[]
[]
[Trainers<<<{"href": "../../../syntax/Trainers/index.html"}>>>]
[poly_reg_T_avg]
type = PolynomialRegressionTrainer<<<{"description": "Computes coefficients for polynomial regession model.", "href": "../../../source/trainers/PolynomialRegressionTrainer.html"}>>>
sampler<<<{"description": "Sampler used to create predictor and response data."}>>> = csv
predictor_cols<<<{"description": "Sampler columns used as the independent random variables, If 'predictors' and 'predictor_cols' are both empty, all sampler columns are used."}>>> = '0 1 2 3'
response<<<{"description": "Reporter value of response results, can be vpp with <vpp_name>/<vector_name> or sampler column with 'sampler/col_<index>'."}>>> = sampling_matrix/T_avg
max_degree<<<{"description": "Maximum polynomial degree to use for the regression."}>>> = 3
regression_type<<<{"description": "The type of regression to perform."}>>> = OLS
cv_type<<<{"description": "Cross-validation method to use for dataset. Options are 'none' or 'k_fold'."}>>> = K_FOLD
cv_surrogate<<<{"description": "Name of Surrogate object used for model cross-validation."}>>> = pr_T_avg
[]
[]
[Surrogates<<<{"href": "../../../syntax/Surrogates/index.html"}>>>]
[pr_T_avg]
type = PolynomialRegressionSurrogate<<<{"description": "Evaluates polynomial regression model with coefficients computed from PolynomialRegressionTrainer.", "href": "../../../source/surrogates/PolynomialRegressionSurrogate.html"}>>>
trainer<<<{"description": "The SurrogateTrainer object. If this is specified the trainer data is automatically gathered and available in this SurrogateModel object."}>>> = poly_reg_T_avg
[]
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
json<<<{"description": "Output Reporter values to a *.json file using the default JSON output."}>>> = true
[]