Deep Reinforcement Learning Control Using Libtorch
The following example demonstrates how to set up a Proximal Policy Optimization (PPO) based Deep Reinforcement Learning (DRL) training sequence for neural-net-based controllers of MOOSE simulations. See Schulman et al. (2017) for a more theoretical background on the PPO algorithm.
Problem Statement
In this example we would like to design a DRL-based controller for the air conditioning of a room. The room in this problem is a 2D box shown in Figure 1:
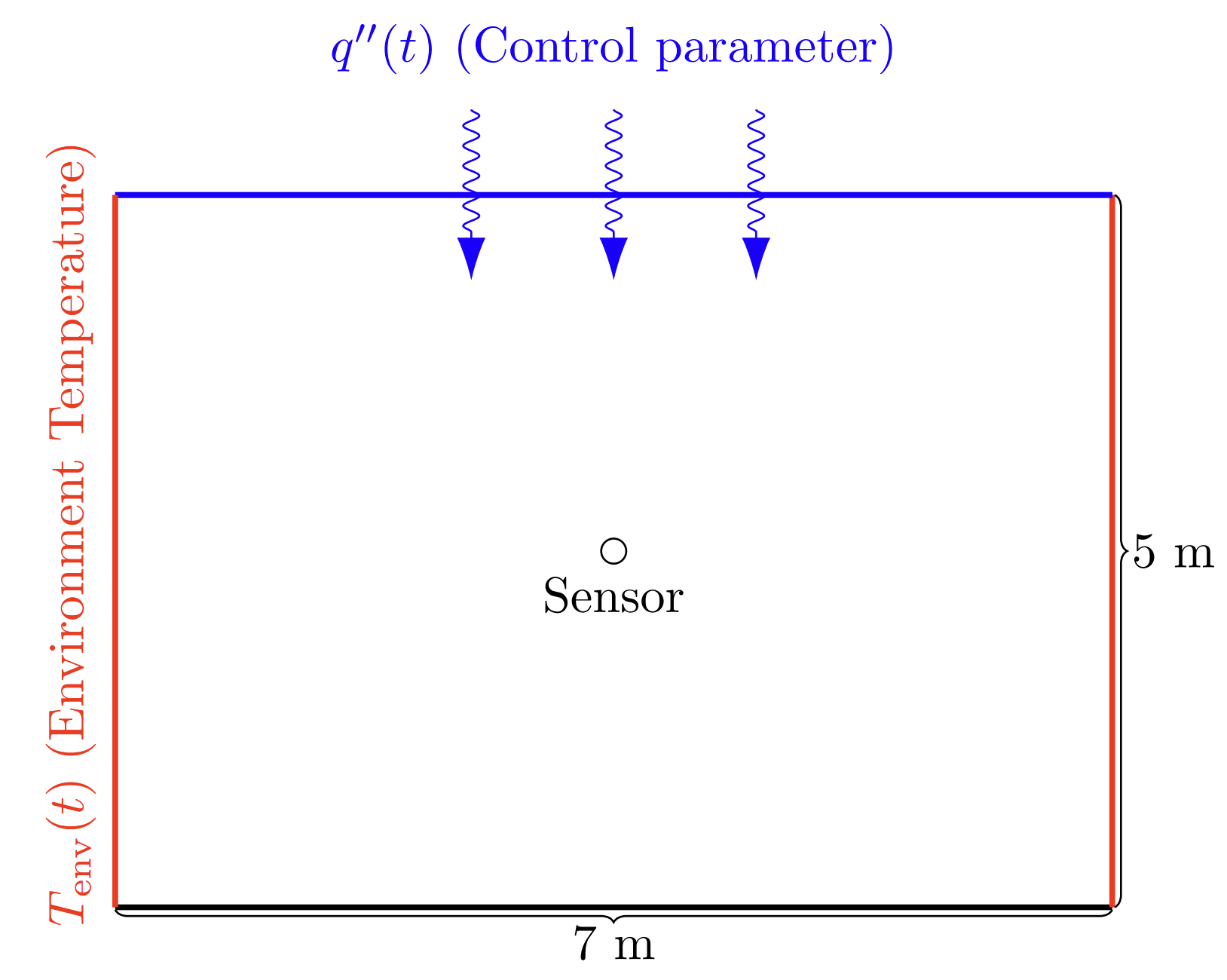
Figure 1: Problem setup for the DRL control example.
The control problem can then be defined as follows: control the heat flux at the top of the box such that the temperature at the sensor position is as close to as possible. For this, we are allowed to use the current and past values of the temperature at the sensor together with the current and past measurements of the environment temperature. Furthermore, we assume the following:
The density of the air is:
The specific heat of the air is:
The effective thermal conductivity (increased to account for mixing effects) is:
The environment temperature is handled as a Dirichlet boundary condition applied to the right and left walls with a value of:
The air conditioner is modeled as a Neumann boundary condition on the top with given heat flux
Input Files
For training a DRL-based controller, we need two input files: a main input file which runs the trainer and another input file which sets up a sub-application that provides data for the training procedure. We start by discussing the sub-application since it showcases the physical problem at hand.
Sub-application
The sub-application input file requires the following parts in order to enable the control functionalities discussed later. First, we need to add a Neumann boundary condition for the top surface:
[BCs<<<{"href": "../../../syntax/BCs/index.html"}>>>]
[top_flux]
type = NeumannBC<<<{"description": "Imposes the integrated boundary condition $\\frac{\\partial u}{\\partial n}=h$, where $h$ is a constant, controllable value.", "href": "../../../source/bcs/NeumannBC.html"}>>>
value<<<{"description": "For a Laplacian problem, the value of the gradient dotted with the normals on the boundary."}>>> = 0.0
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = 'top'
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
[]
[dirichlet]
type = FunctionDirichletBC<<<{"description": "Imposes the essential boundary condition $u=g(t,\\vec{x})$, where $g$ is a (possibly) time and space-dependent MOOSE Function.", "href": "../../../source/bcs/FunctionDirichletBC.html"}>>>
function<<<{"description": "The forcing function."}>>> = temp_env
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = 'left right'
[]
[]The "value" parameter of the boundary condition will be controlled by the neural network. The environment temperature (dirichlet) is defined to be a function of time (temp_env), which is specified in the Functions block:
[Functions<<<{"href": "../../../syntax/Functions/index.html"}>>>]
[temp_env]
type = ParsedFunction<<<{"description": "Function created by parsing a string", "href": "../../../source/functions/MooseParsedFunction.html"}>>>
expression<<<{"description": "The user defined function."}>>> = '15.0*sin(t/86400.0*pi) + 273.0'
[]
[design_function]
type = ParsedFunction<<<{"description": "Function created by parsing a string", "href": "../../../source/functions/MooseParsedFunction.html"}>>>
expression<<<{"description": "The user defined function."}>>> = '297'
[]
[reward_function]
type = ScaledAbsDifferenceDRLRewardFunction<<<{"description": "Evaluates a scaled absolute difference reward function for a process which is controlled by a Deep Reinforcement Learning based surrogate.", "href": "../../../source/functions/ScaledAbsDifferenceDRLRewardFunction.html"}>>>
design_function<<<{"description": "The desired value to reach."}>>> = design_function
observed_value<<<{"description": "The name of the Postprocessor that contains the observed value."}>>> = center_temp_tend
c1<<<{"description": "1st coefficient in the reward function."}>>> = 1
c2<<<{"description": "2nd coefficient in the reward function."}>>> = 10
[]
[]This block also contains the function definition for the target temperature and the reward function. For this experiment, we set the target temperature (design_function) to be , while the reward function (reward_function), defined by ScaledAbsDifferenceDRLRewardFunction, is used for the training.
Next, we set up the data collection using the Postprocessors and Reporters blocks:
[Postprocessors<<<{"href": "../../../syntax/Postprocessors/index.html"}>>>]
[center_temp]
type = PointValue<<<{"description": "Compute the value of a variable at a specified location", "href": "../../../source/postprocessors/PointValue.html"}>>>
variable<<<{"description": "The name of the variable that this postprocessor operates on."}>>> = T
point<<<{"description": "The physical point where the solution will be evaluated."}>>> = '3.5 2.5 0.0'
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'INITIAL TIMESTEP_BEGIN'
[]
[center_temp_tend]
type = PointValue<<<{"description": "Compute the value of a variable at a specified location", "href": "../../../source/postprocessors/PointValue.html"}>>>
variable<<<{"description": "The name of the variable that this postprocessor operates on."}>>> = T
point<<<{"description": "The physical point where the solution will be evaluated."}>>> = '3.5 2.5 0.0'
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'INITIAL TIMESTEP_END'
[]
[env_temp]
type = FunctionValuePostprocessor<<<{"description": "Computes the value of a supplied function at a single point (scalable)", "href": "../../../source/postprocessors/FunctionValuePostprocessor.html"}>>>
function<<<{"description": "The function which supplies the postprocessor value."}>>> = temp_env
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'INITIAL TIMESTEP_BEGIN'
[]
[reward]
type = FunctionValuePostprocessor<<<{"description": "Computes the value of a supplied function at a single point (scalable)", "href": "../../../source/postprocessors/FunctionValuePostprocessor.html"}>>>
function<<<{"description": "The function which supplies the postprocessor value."}>>> = reward_function
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'INITIAL TIMESTEP_END'
indirect_dependencies<<<{"description": "If the evaluated function depends on other postprocessors they must be listed here to ensure proper dependency resolution"}>>> = 'center_temp_tend env_temp'
[]
[top_flux]
type = LibtorchControlValuePostprocessor<<<{"description": "Reports the value stored in given controlled parameters.", "href": "../../../source/libtorch/postprocessors/LibtorchControlValuePostprocessor.html"}>>>
control_name<<<{"description": "The name of the LibtorchNeuralNetControl object."}>>> = src_control
[]
[log_prob_top_flux]
type = LibtorchDRLLogProbabilityPostprocessor<<<{"description": "Computes the logarithmic probability of the action in a given LibtorchDRLController.", "href": "../../../source/libtorch/postprocessors/LibtorchDRLLogProbabilityPostprocessor.html"}>>>
control_name<<<{"description": "The name of the LibtorchNeuralNetControl object."}>>> = src_control
[]
[]Two of these postprocessors measure the temperature at the location of the sensor. center_temp stores the value at the beginning of the time step, while center_temp_tend stores it at the end of the time step. This is due to the fact that the neural network needs the measured temperature at the beginning of the time step, while we would like to compute the reward for the training process using the temperature at the end of the time step. Furthermore, the trainer needs the environment temperature and the reward values as well. Additionally, we save the action (top_flux) of the neural net together with its logarithmic probability (log_prob_top_flux). Our control object will be responsible to populate these two postprocessors. Finally, we create an AccumulateReporter to store every data point throughout the simulation:
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[T_reporter]
type = AccumulateReporter<<<{"description": "Reporter which accumulates the value of a inputted reporter value over time into a vector reporter value of the same type.", "href": "../../../source/reporters/AccumulateReporter.html"}>>>
reporters<<<{"description": "The reporters to accumulate."}>>> = 'center_temp_tend/value env_temp/value reward/value top_flux/value log_prob_top_flux/value'
[]
[]The last step is to set up the neural-net-based controller for the input file:
[Controls<<<{"href": "../../../syntax/Controls/index.html"}>>>]
inactive<<<{"description": "If specified blocks matching these identifiers will be skipped."}>>> = 'src_control_final'
[src_control]
type = LibtorchDRLControl<<<{"description": "Sets the value of multiple 'Real' input parameters and postprocessors based on a Deep Reinforcement Learning (DRL) neural network trained using a PPO algorithm.", "href": "../../../source/libtorch/controls/LibtorchDRLControl.html"}>>>
parameters<<<{"description": "The input parameter(s) to control."}>>> = "BCs/top_flux/value"
responses<<<{"description": "The responses (prostprocessors) which are used for the control."}>>> = 'center_temp_tend env_temp'
# keep consistent with LibtorchDRLControlTrainer
input_timesteps<<<{"description": "Number of time steps to use in the input data, if larger than 1, data from the previous timesteps will be used as well as inputs in the training."}>>> = 2
response_scaling_factors<<<{"description": "Constants which will be used to multiply the shifted response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '0.03 0.03'
response_shift_factors<<<{"description": "Constants which will be used to shift the response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '290 290'
action_standard_deviations<<<{"description": "Standard deviation value used while sampling the actions."}>>> = '0.02'
action_scaling_factors<<<{"description": "Scale factor that multiplies the NN output to obtain a physically meaningful value."}>>> = 200
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'TIMESTEP_BEGIN'
[]
[src_control_final]
type = LibtorchNeuralNetControl<<<{"description": "Controls the value of multiple controllable input parameters using a Libtorch-based neural network.", "href": "../../../source/libtorch/controls/LibtorchNeuralNetControl.html"}>>>
filename<<<{"description": "Define if the neural net is supposed to be loaded from a file."}>>> = 'mynet_control.net'
num_neurons_per_layer<<<{"description": "The number of neurons on each hidden layer."}>>> = '16 6'
activation_function<<<{"description": "The type of activation functions to use. It is either one value or one value per hidden layer."}>>> = 'relu'
parameters<<<{"description": "The input parameter(s) to control."}>>> = "BCs/top_flux/value"
responses<<<{"description": "The responses (prostprocessors) which are used for the control."}>>> = 'center_temp_tend env_temp'
# keep consistent with LibtorchDRLControlTrainer
input_timesteps<<<{"description": "Number of time steps to use in the input data, if larger than 1, data from the previous timesteps will be used as well as inputs in the training."}>>> = 2
response_scaling_factors<<<{"description": "Constants which will be used to multiply the shifted response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '0.03 0.03'
response_shift_factors<<<{"description": "Constants which will be used to shift the response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '290 290'
action_standard_deviations = '0.02'
action_scaling_factors<<<{"description": "Scale factor that multiplies the NN output to obtain a physically meaningful value."}>>> = 200
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'TIMESTEP_BEGIN'
[]
[]For this, we need to supply the controllable parameters using parameters. Then, we supply the neural net inputs using responses. Lastly we define the scaling of the input (responses) and the output of the neural net. These must be consistent with the values of the LibtorchDRLControlTrainer object in the main application. The containers for the control signal and its logarithmic probability are defined in the Postprocessors block using LibtorchControlValuePostprocessor and LibtorchDRLLogProbabilityPostprocessor as shown above. Furthermore, the additional LibtorchNeuralNetControl (src_control_final) can be used to evaluate the neural network without the additional random sampling process needed for the training process. In other words, this object will evaluate the final product of this training process.
Main Application
The input for the main application starts with the definition of a Sampler. In this example we do not aim to train a controller which can adapt to random model parameters, so we just define a dummy sampler which does not rely on random numbers.
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[dummy]
type = CartesianProduct<<<{"description": "Provides complete Cartesian product for the supplied variables.", "href": "../../../source/samplers/CartesianProductSampler.html"}>>>
linear_space_items<<<{"description": "A list of triplets, each item should include the min, step size, and number of steps."}>>> = '0 0.01 1'
[]
[]In case we would like to increase the flexibility of the neural-net based controller, this sampler can be switched to something that can scan the uncertain input parameter space.
Following this, a MultiApp is created to run the sub-application many times for data generation:
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerFullSolveMultiApp<<<{"description": "Creates a full-solve type sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerFullSolveMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = dummy
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'libtorch_drl_control_sub.i'
[]
[]We also require transfers between the applications. We pull the data of the simulations from the MultiApp using MultiAppReporterTransfer.
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[nn_transfer]
type = LibtorchNeuralNetControlTransfer<<<{"description": "Copies a neural network from a trainer object on the main app to a LibtorchNeuralNetControl object on the subapp.", "href": "../../../source/libtorch/transfers/LibtorchNeuralNetControlTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
trainer_name<<<{"description": "Trainer object that contains the neural networks. for different samples."}>>> = nn_trainer
control_name<<<{"description": "Controller object name."}>>> = src_control
[]
[r_transfer]
type = MultiAppReporterTransfer<<<{"description": "Transfers reporter data between two applications.", "href": "../../../source/transfers/MultiAppReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
to_reporters<<<{"description": "List of the reporter names (object_name/value_name) to transfer the value to."}>>> = 'results/center_temp results/env_temp results/reward results/top_flux results/log_prob_top_flux'
from_reporters<<<{"description": "List of the reporter names (object_name/value_name) to transfer the value from."}>>> = 'T_reporter/center_temp_tend:value T_reporter/env_temp:value T_reporter/reward:value T_reporter/top_flux:value T_reporter/log_prob_top_flux:value'
[]
[]The neural network trained by LibtorchDRLControlTrainer needs to be transferred to the control object in the sub-application. We do this using LibtorchNeuralNetControlTransfer. Finally, we can set up our trainer object for the problem:
[Trainers<<<{"href": "../../../syntax/Trainers/index.html"}>>>]
[nn_trainer]
type = LibtorchDRLControlTrainer<<<{"description": "Trains a neural network controller using the Proximal Policy Optimization (PPO) algorithm.", "href": "../../../source/libtorch/trainers/LibtorchDRLControlTrainer.html"}>>>
response<<<{"description": "Reporter values containing the response values from the model."}>>> = 'results/center_temp results/env_temp'
control<<<{"description": "Reporters containing the values of the controlled quantities (control signals) from the model simulations."}>>> = 'results/top_flux'
log_probability<<<{"description": "Reporters containing the log probabilities of the actions taken during the simulations."}>>> = 'results/log_prob_top_flux'
reward<<<{"description": "Reporter containing the earned time-dependent rewards from the simulation."}>>> = 'results/reward'
num_epochs<<<{"description": "Number of epochs for the training."}>>> = 1000
update_frequency<<<{"description": "Number of transient simulation data to collect for updating the controller neural network."}>>> = 10
decay_factor<<<{"description": "Decay factor for calculating the return. This accounts for decreased reward values from the later steps."}>>> = 0.0
loss_print_frequency<<<{"description": "The frequency which is used to print the loss values. If 0, the loss values are not printed."}>>> = 10
critic_learning_rate<<<{"description": "Learning rate (relaxation) for the emulator training."}>>> = 0.0001
num_critic_neurons_per_layer<<<{"description": "Number of neurons per layer in the emulator neural net."}>>> = '64 27'
control_learning_rate<<<{"description": "Learning rate (relaxation) for the control neural net training."}>>> = 0.0005
num_control_neurons_per_layer<<<{"description": "Number of neurons per layer for the control neural network."}>>> = '16 6'
# keep consistent with LibtorchNeuralNetControl
input_timesteps<<<{"description": "Number of time steps to use in the input data, if larger than 1, data from the previous timesteps will be used as inputs in the training."}>>> = 2
response_scaling_factors<<<{"description": "A normalization constant which will be used to divide the response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '0.03 0.03'
response_shift_factors<<<{"description": "A shift constant which will be used to shift the response values. This is used for the manipulation of the neural net inputs for better training efficiency."}>>> = '290 290'
action_standard_deviations<<<{"description": "Standard deviation value used while sampling the actions."}>>> = '0.02'
standardize_advantage<<<{"description": "Switch to enable the shifting and normalization of the advantages in the PPO algorithm."}>>> = true
read_from_file<<<{"description": "Switch to read the neural network parameters from a file."}>>> = false
[]
[]The trainer object will need the names of the reporters containing the responses (input of the neural net) of the system together with the control signals, control signal logarithmic probabilities, and the rewards. When these are set, we define the architecture of the critic and control neural nets (see Schulman et al. (2017) for more information on these) using "num_critic_neurons_per_layer" and "num_control_neurons_per_layer". The corresponding learning rates can be defined by "critic_learning_rate" and "control_learning_rate". Then, we copy-paste the input/output standardization options from the Control in the sub-app. Additionally, we can choose to standardize the advantage function which makes convergence more robust in certain scenarios.
Lastly, we request 1,000 epochs for training the neural networks in each iteration and collect data from 10 simulations on the sub-app every time step of the main app. We set the iteration number by setting the number of time steps below:
[Executioner<<<{"href": "../../../syntax/Executioner/index.html"}>>>]
type = Transient
num_steps = 440
[]Which means that we run a total of 440 simulations.
Results
First, we take a look at how the average episodic reward evolves throughout the training process. We see that the average reward increases to a point where it is comparable with the theoretical maximum.
In this example we used ScaledAbsDifferenceDRLRewardFunction as follows: which means that the maximum achievable reward was 10.
However, it is important to note that the higher the standard deviation is for the controllers signal to the system (also referred to as action), the more flexible the controller will be (due to less overfitting). On the other hand, by increasing the random variation in the action, we also decrease its accuracy. Therefore, the user needs to balance these two factors by tuning the parameters in the Trainer and Control objects.
Figure 2: The evolution of the reward values over the iteration.
Following the training procedure, we can replace the LibtorchDRLControl object with LibtorchNeuralNetControl to evaluate the final version of the neural network without the additional randomization. By doing this, the following results are obtained:
Figure 3: The evolution of the room temperature at the sensor over the day.
We see that the controller is able to maintain the comfortable room temperature with a constantly changing environment temperature.
References
- John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov.
Proximal policy optimization algorithms.
arXiv preprint arXiv:1707.06347, 2017.[Export]